一、範圍和目的:
◇The Science of visualization
through learning what perception is and how perception works.
◇這是一門science,而不是art,學視知覺不一定確保能做出好的設計,但可以有效防止做出bad
design。
◇視覺科學是20世紀進步最大、成就最豐富的一門學科。
二、資訊視覺化的優點
◇我們仰賴視覺作決策(decision making)。
ex: 擇偶:人是視覺性的動物(研究發現女性身體健康=美,因為健康的身體,使身體不受外力影響, 成長對稱的五官,達到美的基本要素,美的標準進入生物學的領域,仍有許多可以應用的地方)。
基本上,生物性的美的標準(偏好)是亙古不變的(基調),但是每個時代的社會因素影響是加諸於上的(小幅修正),因此,從小在不美的環境下長大的人並不會因此以醜為美。
老師撇清:提出擇偶之說並非有所偏見、只是陳述一種現象 ◇視覺系統處理的是頻寬很大的資訊量。
◆視覺功能佔大腦一半以上的訊息處理資源(information-processing)
◆視覺處理是非常耗費資源的事,每秒從眼中獲得的訊息量,約是30冊/300 頁/400-500字
的百科全書。
 (圖一)New England 海水潮汐洋流變化圖:是由一百萬筆資料合成 (圖一)New England 海水潮汐洋流變化圖:是由一百萬筆資料合成 (立體3D有凹凸的圖片),要解讀這張圖比解讀長條圖或數據容易得多。 |
◇視覺化有助於觀察出以其他資料呈現方式不易察覺到的資料特性。
◇視覺化以後可以很容易看出本身的瑕疵與錯誤。
ex : 以(圖一)為例,有一排排的陰影處,是收集數據時沒有考慮船隊本身排列方式對洋流造成影響所產生。
◇視覺化資料可以同時見樹又見林。
◇視覺化資料對於形成新的理解知識非常重要。
◇20世紀末,Scientific visualization研討會中提到,當知識越來越複雜、龐大,我們如何使知識有更好的呈現方式,即是「視覺化」。
三、資訊視覺化:符號學與知覺的觀點
◇符號學:探討符號文字如何傳達其意義的學問,過去符號學者多是哲學家或語言學家。
◇傳統符號學者的文化決定論:所有符號系統在每個完化中都是最好的、最適切得,沒有優劣之分。
◇Saussure's principle of
arbitrariness.(隨意武斷與約定俗成的),但,視覺的符號並不是arbitrariness
(曾有人類學家研究指出非洲婦女無法理解照片圖像,此類報導實缺失甚多)
◇Hochberg & Brooks(1962)進行「視覺剝奪研究」,將自己女兒刻意置於避開任何圖像符號的環境,
直到五歲才給予圖像,他仍能辨別,與文化相對論的符號學者持極端相反的意見,他認為人類視覺對符號的認知是具有生物性的。
◇圖片的理解,以感官為基礎還是以文化為基礎?中國人講「執兩用中」,因此現在的符號使用不完全極端,
而介於之中,不完全穿透(cave painting)也非完全不穿透(equation),大多數的視覺符號也都是介於兩者之間。但
在這門課中所提會較偏於前者。
◇sensory code 感覺符號 v.s. conventional code 約定符號sensory code是容易以科學的方法來研究(也就是這門課的方向),但並不表示只有sensory
code是藝術的唯一,
勿陷入一種二元的對立思考。
貳、
一、感覺表徵的特性
1.Uunderstanding without training
ex : 洞窟壁畫不言可喻
2.Resistance to instructional bias任何指導性命令無效
ex : 視錯覺:無法用理智去改變所看到的東西
3.Sensory immediacy立即可感受、無須花時間去理解
4.Cross-cultural validity越是基本的形象、越是放諸四海皆準。
二、研究感覺表徵問題的方法
1.Psychophysics心理物理學:測量物理刺激對心理經驗品質、程度大小的定量測量(非常powerful的研究方法)
ex:某種聲音會引起哀傷的程度(but如果要探討「哪種」聲音引起哀傷則牽涉到認知心理學的部分)
2.Cognitive Psychology認知心理學
3.Structral Analysis結構性分析:透過結構性問卷進行研究
4.Cross-Cultural Studies:許多基本感官的屬性可以從跨文化的角度去研究,可以探究哪種感官較為「basic基本」 (但是現在要找到在文化上很純正的研究對象十分不容易,因為世界文化的流竄使文化邊界變得十分模糊)
◆感覺與約定的符碼
感覺符碼: Sensory code |
約定符碼: Conventional code |
| (1) 感覺表徵的特性 | (2) 約定符碼的特性 |
| 1. Understanding without training 不學自懂 | 1. Hard to learn 難以學習 |
| 2. Resistance to instructional bias
無法以理智控制 ex : Muller Lyer illusion. |
2. Embedded in Culture & Applications
根植於文化及應用基礎 |
| 3. Sensor immediacy 當下立即的感覺 |
3. Formally Powerful 形式完備、 表義精確 的能力 |
| 4. Cross-Cultural validity 跨文化的理解力 |
4. Capable of rapid change 能夠迅速變動的 |
| (2) 研究感覺表徵問題的方法 | (2) 研究約定符碼問題的方法 |
| 1. Psychopysics 心理物理學 | 1. 文化人類學 |
| 2. Cognitive psychology 認知心理學 | 2. 社會學 |
| 3. Structural analysis 結構性的問卷調查 | 3. 詮釋學等等 |
| 4. Cross-cultural validity 跨文化研究 | |
| 5. Child study 兒童研究 |
5.Child
Study:由於cross-cultural study的不易行,退而求其次則是從孩童進行研究,延續經驗主義的立場,某些根本性的問題可以由孩童研究找到答案。
三、約定符碼的特性與研究方法
1.hard to learn(語言、文字)
2.embedded in culture and application(依附在文化之下)
3.formally powerful(形式上越精緻完備、簡潔精鍊,相反的,sensory
representation就比較難達成)
4.capable of rapid change
研究方法:
1.文化人類學(田野調查、不干擾對象最自然的研究法)
2.社會學(以量化的數據來研究現象,ex:女權思想與離婚率的關係)
3.詮釋學(主動涉入文化的歷程就是研究本身ex:論閨怨)
四、Gibson的affordance理論
(J.J. Gibson二次大站時被美國徵召做飛行研究的視覺心理學家、理論與人因工程極度相關)
Direction Perception:避開不談分析式、階段式的理解,而認為很直接的經驗與affordance相呼應,affordance是透
過知覺去perceived物理環境所提供的行動線索,知覺與行為透過affordance緊密相連,知覺到那個刺激引導你進 行那個行為,若要降低使用錯誤率的研究就必須考量。
◆A Model of Perceptual Processing 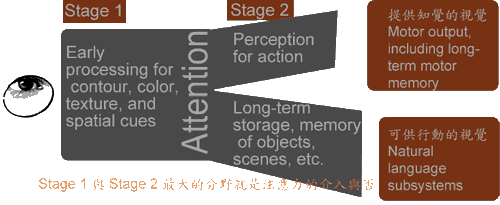 |
資料型態 (Types of Data) :
◆Bertin 於
1977 年提出資料是由兩大成分所組成 :資料量值以及資料結構 。近代描述資料型態習慣用另一種意涵相近但形容方式略異的說法 :資料是由 entities
與 relationships 兩大成分所組成 , entities 是我們欲視覺化的本體,而 relationships 定義了資料的結構樣板用以規範各
entities 之間的關係。我們對 entities 的定義是相當有彈性的,一般說來只要是我們有興趣的物件它就可以被定義為 entities
,一條魚可以是一件 entity ,一群在池塘的魚也可以是一件 entity ,視其方便而定。同樣的,我們對 relationships
的定義也是相當具有彈性的,它可以是實體的關係,如同汽車與其各個零件間的關係,也可以是概念上的關聯,如汽車與其主人間的關係,甚至兩個事件間的因果性,我們也可以稱作那是兩件事情間的
relationship 。
◆Attributes of entities or relationships :對於資料型態更為精準的說法應該再加入 attributes 這個成分 。一般我們將 entity 某些無法單獨表意的特徵稱作 attribute ,例如水果的顏色即為水果的 attribute 。如同 entities 與 relationships , attributes 的定義也是相當有彈性的,例如我們可以認定員工的薪水是員工這個 entity 的 attribute ,同樣的我們也可以把薪水自身定義為一 attribute ,端視我們怎麼定義資料的型態。
◆Attribute quality :根據 S. S. Stevens (1946) 的定義 ,描述 attribute 的方式可分作四級, nominal , ordinal , interval ,以及 ratio scales 。 Nominal 如同標籤,運用名詞去描述物體,即使使用了數字的方式其功用也僅為標定而非排序。 Ordinal 則為一排序性的動作,參雜主客觀的因素,作出喜好程度的排列。 Interval 的用意在於標定各資料的差異程度。 Ratio 的功用類似 interval ,只是它使用了相對性而非絕對性去偵測資料間的關係。在實際的運用上,通常是使用三級的測量方式, category data , integer data , real-number data 。 Category data 可類比至 nominal level ,而 integer data 可類比至 ordinal level ,至於 real-number data 則類比至 interval 與 ratio level 。
◆Operations considered as data :若要使資料類別的定義更為完整 ,或許需要再加入 operations 這項元素。數學運算、邏輯運算、物理反應、化學反應等等均屬其範疇, Entities 經過 operations 可能產生新的 entities 或是消失。有些 operations 要以視覺化來表示並不大容易,哪些適用視覺化的表示以及哪些不適用視覺化的表達這又是另一門課題。
◆Metadata :隨著對資料的了解程度越來越佳 ,我們所能定義的資料型態也就越來越細膩,然而有些資料卻非直接可見的,有時需要透過一些 operations 才可顯現出來,這類的資料被稱作 metadata ( Tweedie , 1997) ,如原子、電子、電洞 … 隨著資料型態定義的越來越精細,在使用這些名詞的同時需要更加注意我們所處的觀察點,處在微觀與巨觀的角度有時觀察到的資料呈現是完全不同的。